Hanqi Jiang (蒋瀚祺)
 Ph.D. Student, The University of Georgia (2024)
Ph.D. Student, The University of Georgia (2024)
I am a second-year PhD student at University of Georgia, supervised by Distinguished Research Professor Tianming Liu. My research focus is Quantum AI & Medical Image Analysis & Brain-inspired AI. If you are seeking any form of academic cooperation, please feel free to email me at hanqi.jiang@uga.edu (UGA) or hjiang81@mgh.harvard.edu (MGH).

Education
-
University of Georgia
Ph.D. in Computer Science Sep. 2024 - Now
-

Lancaster University
B.S. in Computer Science (First-Class Honored) Sep. 2019 - Jul. 2023
-

Beijing Jiaotong University
B.Eng. in Computer Science Sep. 2019 - Jul. 2023
Honors & Awards
- NSF Student Travel Award, AAAI FSS25 (QIML) 2025
- Outstanding Graduation Project of Beijing Province 2023
Experience
-
School of Computing, UGA
Research Assistant & Teaching Assistant Sep. 2024 - Now
-

Center for Advanced Medical Computing and Analysis (CAMCA), MGB/Harvard Medical School
Radiology Research Mar. 2025 - Now
-

School of Data Science, CUHK(SZ)
Research Assistant Jul. 2023 - Sep. 2023
Service
- Reviewer of IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- Reviewer of IEEE Transactions on Artificial Intelligence (TAI)
- Reviewer of IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
- Reviewer of IEEE Transactions on Image Processing
- Reviewer of Medical Image Analysis
- Reviewer of NeurIPS, ICLR, ECCV, AAAI, MICCAI, ISBI
News
Selected Publications
(view all ) 
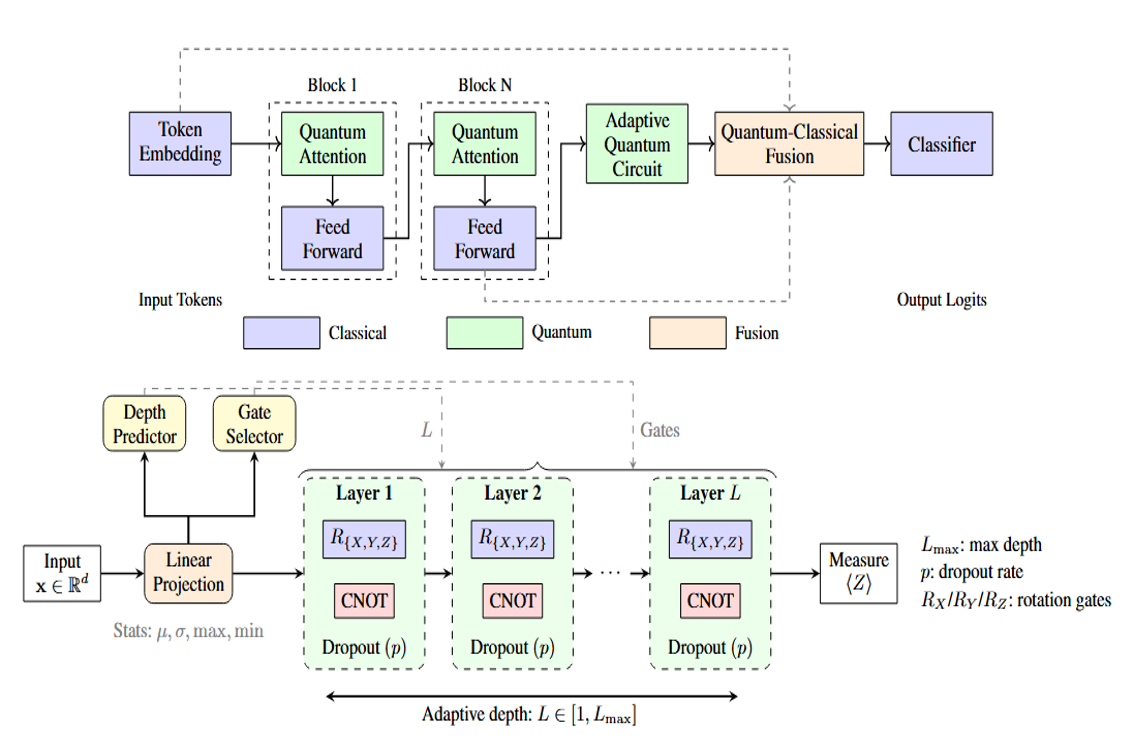
Bridging Classical and Quantum Computing for Next-Generation Language Models
Yi Pan*, Hanqi Jiang*, Junhao Chen, Yiwei Li, Huaqin Zhao, Lin Zhao, Yohannes Abate, Yingfeng Wang†, Tianming Liu†(* equal contribution)(† corresponding author)
AAAI QIML 2025 Conference
We introduce Adaptive Quantum-Classical Fusion (AQCF), the first framework to bridge quantum and classical computing through dynamic, quantum-classical co-design for next-generation language models. We introduce Adaptive Quantum-Classical Fusion (AQCF), the first framework to bridge quantum and classical computing through dynamic, quantum-classical co-design for next-generation language models. Read more
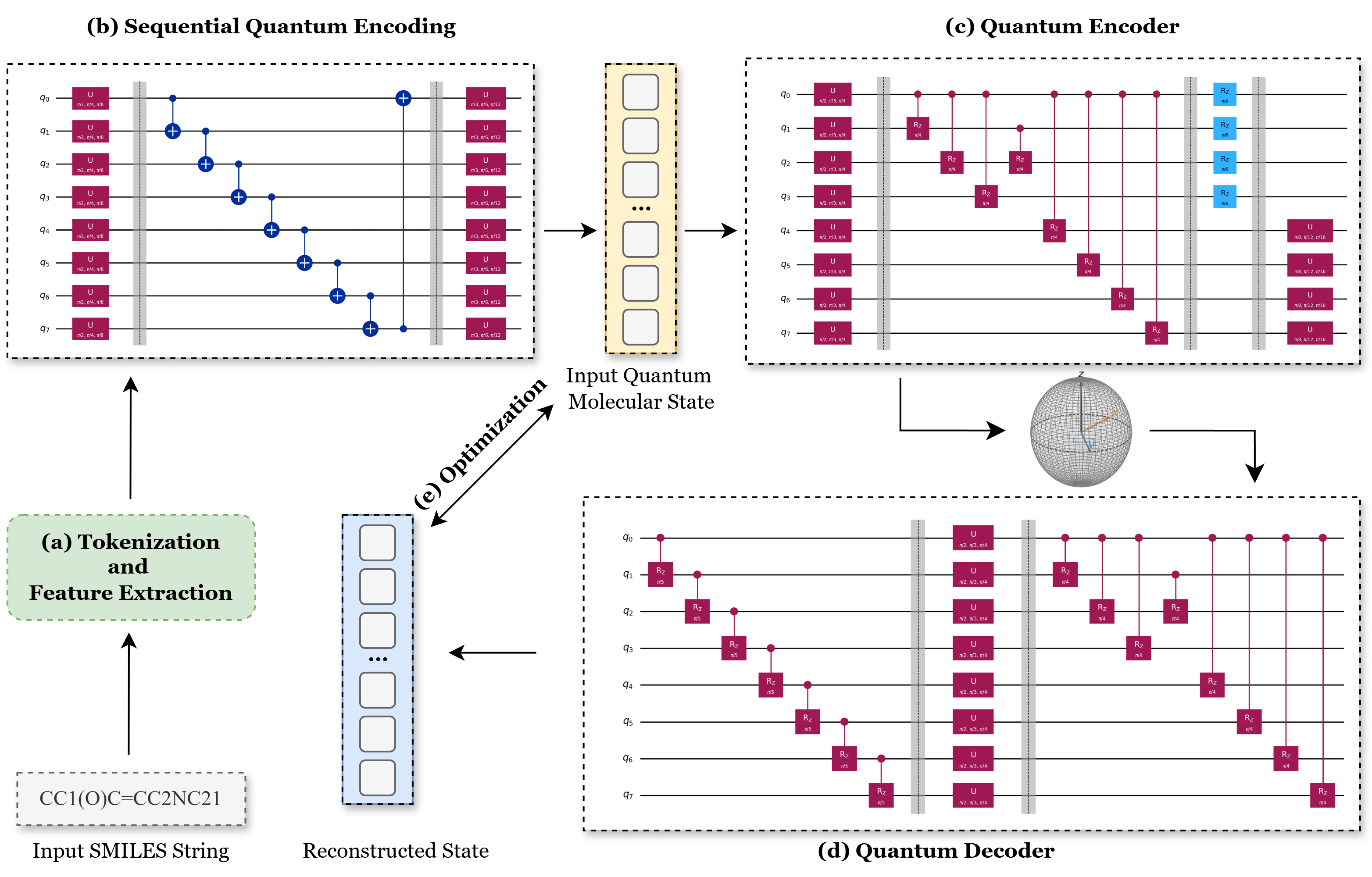
MolQAE: Quantum Autoencoder for Molecular Representation Learning
Yi Pan*, Hanqi Jiang*, Wei Ruan, Dajiang Zhu, Xiang Li, Yohannes Abate, Yingfeng Wang†, Tianming Liu†(* equal contribution)(† corresponding author)
QAI 2025 Conference
Quantum Autoencoder for Molecular Representation Learning. Quantum Autoencoder for Molecular Representation Learning. Read more
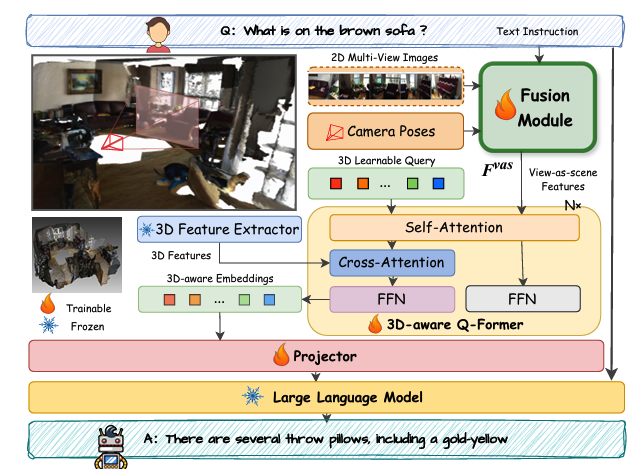
Argus: Leveraging Multi-View Images for Improved 3D Scene Understanding with Large Language Models
Yifan Xu, Chao Zhang, Hanqi Jiang, Xiaoyan Wang, Ruifei Ma, Yiwei Li, Zihao Wu, Zeju Li, Xiangde Liu†(† corresponding author)
IEEE Transactions on Neural Networks and Learning Systems 2025 Journal (IF=10.2)
Leveraging Multi-View Images for Improved 3D Scene Understanding with Large Language Models. Leveraging Multi-View Images for Improved 3D Scene Understanding with Large Language Models. Read more
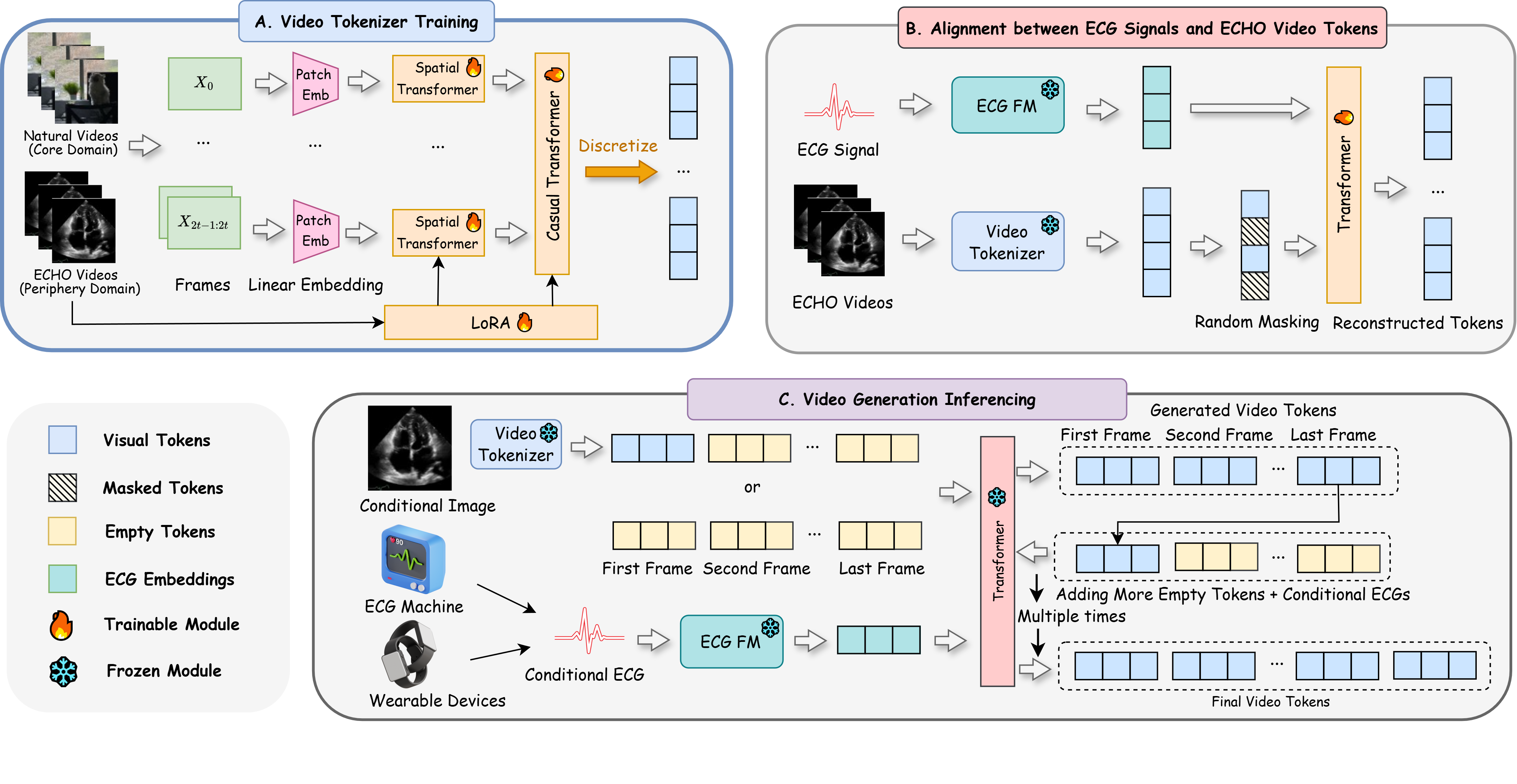
ECHOPulse: ECG Controlled Echocardiograms Video Generation
Yiwei Li, Sekeun Kim, Zihao Wu, Hanqi Jiang, Yi Pan, Pengfei Jin, Sifan Song, Yucheng Shi, Xiaowei Yu, Tianze Yang, Tianming Liu†, Quanzheng Li†, Xiang Li†(† corresponding author)
ICLR 2025 Conference
We propose ECHOPluse, an ECG-conditioned ECHO video generation model. ECHOPluse introduces two key advancements: (1) it accelerates ECHO video generation by leveraging VQ-VAE tokenization and masked visual token modeling for fast decoding, and (2) it conditions on readily accessible ECG… We propose ECHOPluse, an ECG-conditioned ECHO video generation model. ECHOPluse introduces two key advancements: (1) it accelerates ECHO video generation by leveraging VQ-VAE tokenization and masked visual token modeling for fast decoding, and (2) it conditions on readily accessible ECG signals, which are highly coherent with ECHO videos, bypassing complex conditional prompts. To the best of our knowledge, this is the first work to use time-series prompts like ECG signals for ECHO video generation. ECHOPluse not only enables controllable synthetic ECHO data generation but also provides updated cardiac function information for disease monitoring and prediction beyond ECG alone. Evaluations on three public and private datasets demonstrate state-of-the-art performance in ECHO video generation across both qualitative and quantitative measures. Read more
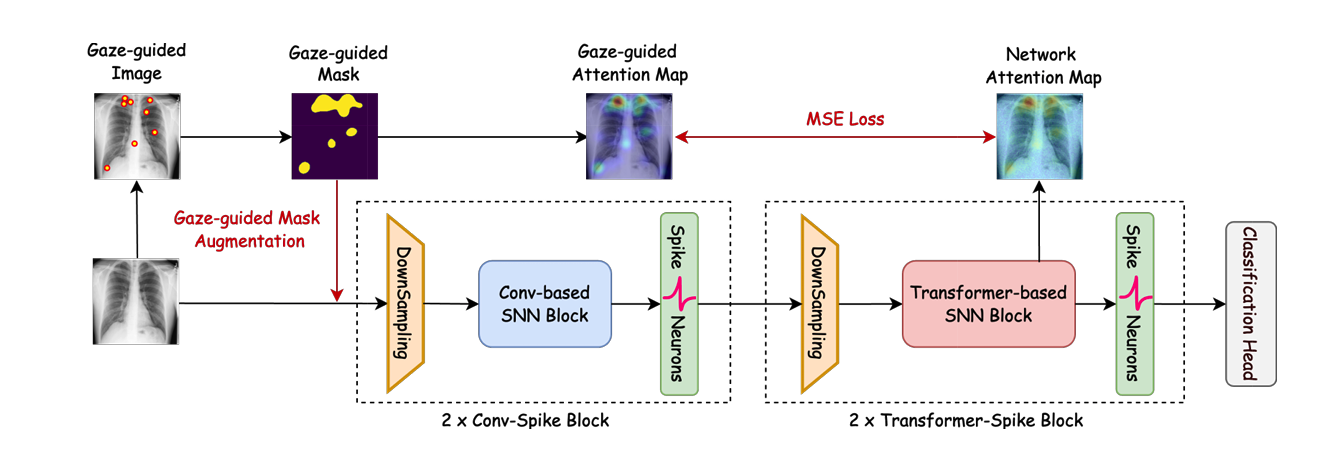
EG-SpikeFormer: Eye-Gaze Guided Transformer on Spiking Neural Networks for Medical Image Analysis
Yi Pan*, Hanqi Jiang*, Junhao Chen, Yiwei Li, Huaqin Zhao, Yifan Zhou, Peng Shu, Zihao Wu, Zhengliang Liu, Dajiang Zhu, Xiang Li, Yohannes Abate, Tianming Liu†(* equal contribution)(† corresponding author)
ISBI 2025 Oral Conference
Eye-Gaze Guided Transformer on Spiking Neural Networks for Medical Image Analysis. Eye-Gaze Guided Transformer on Spiking Neural Networks for Medical Image Analysis. Read more
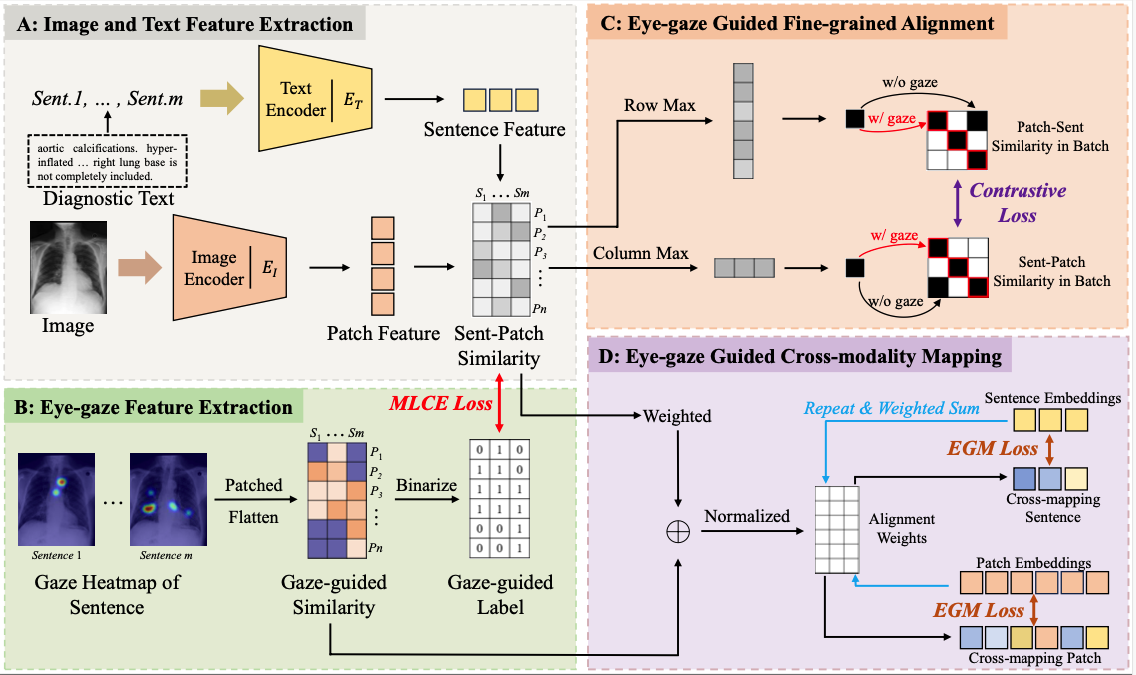
Eye-gaze Guided Multi-modal Alignment for Medical Representation Learning
Chong Ma, Hanqi Jiang, Wenting Chen, Yiwei Li, Zihao Wu, Xiaowei Yu, Zhengliang Liu, Lei Guo, Dajiang Zhu, Tuo Zhang, Dinggang Shen, Tianming Liu†, Xiang Li†(† corresponding author)
NeurIPS 2024 Conference
We propose EGMA, a novel framework for medical multi-modal alignment, marking the first attempt to integrate eye-gaze data into vision-language pre-training. EGMA outperforms existing state-of-the-art medical multi-modal pre-training methods, and realizes notable enhancements in image classification and image-text retrieval tasks.… We propose EGMA, a novel framework for medical multi-modal alignment, marking the first attempt to integrate eye-gaze data into vision-language pre-training. EGMA outperforms existing state-of-the-art medical multi-modal pre-training methods, and realizes notable enhancements in image classification and image-text retrieval tasks. EGMA demonstrates that even a small amount of eye-gaze data can effectively assist in multi-modal pre-training and improve the feature representation ability of the model. Read more
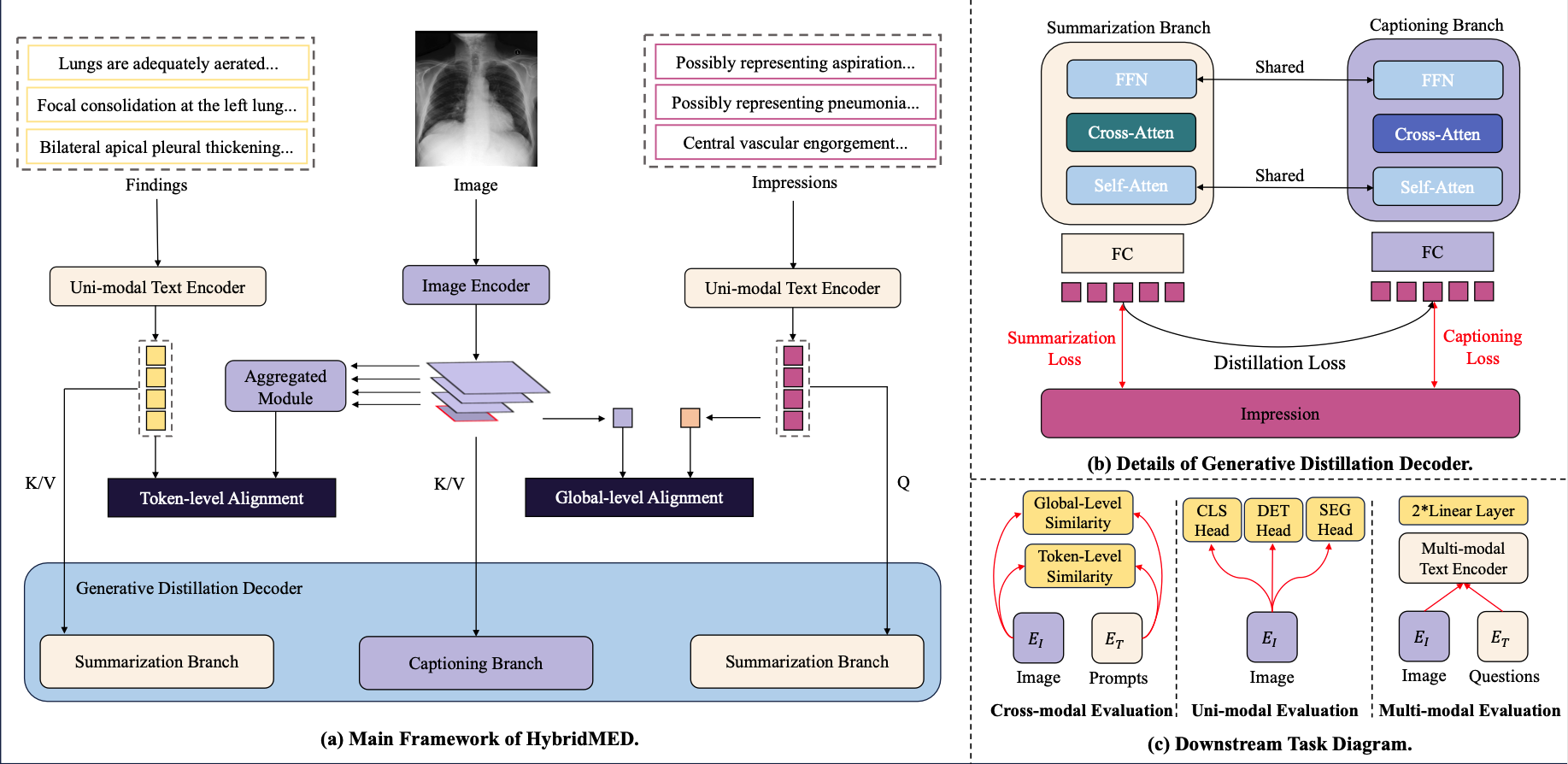
Advancing Medical Radiograph Representation Learning: A Hybrid Pre-training Paradigm with Multilevel Semantic Granularity
Hanqi Jiang, Xixuan Hao, Yuzhou Huang, Chong Ma, Jiaxun Zhang, Yi Pan, Ruimao Zhang†(† corresponding author)
ECCV Workshop 2024 Conference
We present a medical vision-language pre-training (Med-VLP) framework that incorporates multi-modal contrastive alignment and parallel generative streams with multi-level semantic hierarchies. To accomplish this goal, we effectively leverage the characteristics of medical data. By optimizing elaborate training objectives, our HybridMED… We present a medical vision-language pre-training (Med-VLP) framework that incorporates multi-modal contrastive alignment and parallel generative streams with multi-level semantic hierarchies. To accomplish this goal, we effectively leverage the characteristics of medical data. By optimizing elaborate training objectives, our HybridMED is capable of efficiently executing a variety of downstream tasks, including cross-modal, uni-modal, and multi-modal types. Extensive experimental results demonstrate that our HybridMED can deliver highly satisfactory performance across a wide array of downstream tasks, thereby validating the model's superiority. Read more