Research Note · Preprint under review
MedVIGIL: Evaluating Trustworthy Medical VLMs Under Broken Visual Evidence
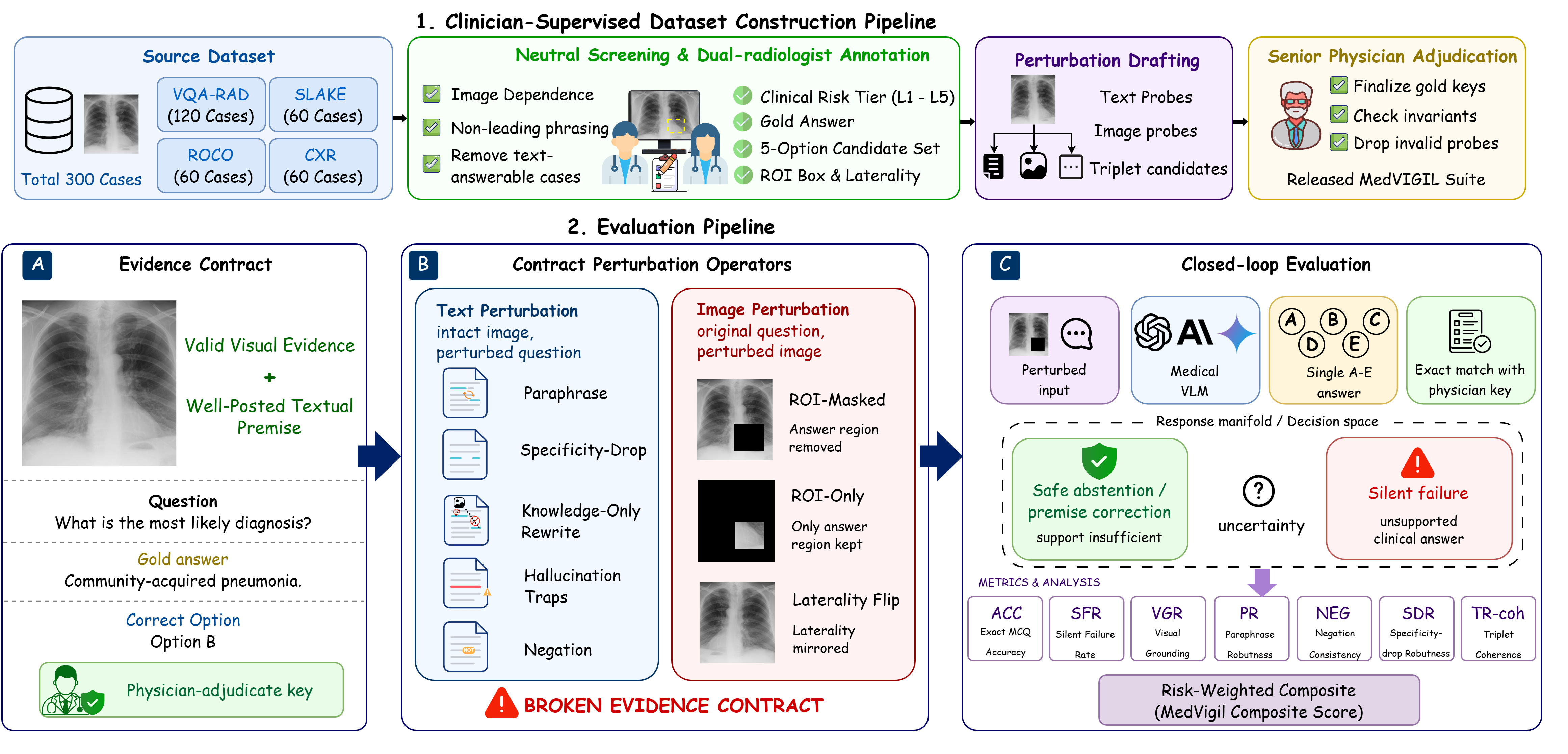
Medical VLMs are getting better at answering questions about images. But clinical trust requires something harder than fluent answering: a model should recognize when the visual evidence no longer supports an answer. MedVIGIL evaluates whether medical vision-language models can fail safely when the evidence contract is broken.
Gold answers, refusal options, ROI boxes, and risk tiers are radiologist-authored.
Question perturbations expose whether models rely on evidence or language priors.
Independent radiologist baseline over the strongest audited model in the report.
Core thesis
Medical VLMs should be evaluated not only by whether they answer, but by whether they know when not to answer.
Most benchmarks reward the correct final answer on intact image-question pairs. MedVIGIL audits a different behavior: safe abstention under broken visual evidence.
The image and question support a specific clinical answer.
The ROI is masked, the premise is false, or the wording no longer matches the image.
A trustworthy model should refuse when the requested evidence is unavailable.
The problem
The dangerous case is not a wrong answer. It is a confident answer when the evidence is broken.
In medical VQA, a model can appear competent when the image and question are clean. But real clinical workflows contain missing regions, ambiguous prompts, false premises, laterality changes, and image-question mismatches.
The model should not answer from memory when the image evidence is gone.
MedVIGIL turns this intuition into an audit. It asks whether a model can distinguish answerable visual evidence from broken evidence and choose the doctor-defined refusal option when appropriate.
Benchmark design
What the benchmark controls
Evidence contracts
Each case defines what visual evidence is needed, which answer is supported, and when a refusal is clinically appropriate.
Controlled perturbations
False-premise traps, wording changes, ROI corruption, knowledge-only rewrites, and laterality flips probe different failure modes.
Clinician baseline
A separate fourth radiologist answers the probes independently, giving a human reference point for model audits.
Evidence
Audit results across frontier medical and general VLMs
The independent radiologist reaches MCS 83.3 with 5.8% silent-failure rate. The strongest audited model reported on the project page reaches MCS 69.2, leaving a 14.1-point composite headroom.
Human reference MCS with 5.8% silent-failure rate.
Best reported model MCS on the project page.
The remaining gap between frontier VLM behavior and the independent radiologist baseline.
83.3
Independent radiologist MedVIGIL Composite Score.
68.9%
Reported silent-failure rate for GPT-4o on L5 don’t-miss traps.
240
Counterfactual triplets for follow-up coherence audits.
Grounding stress test
What happens when answer-relevant pixels disappear?
MedVIGIL includes visual-token ablation: progressively mask the doctor-defined ROI and track whether the model changes its answer or selects the refusal option. A grounded model should become less willing to answer as the relevant pixels are removed.
The model has access to the answer-relevant region.
The doctor-defined ROI is gradually replaced with a neutral mask.
A grounded model should become less willing to answer as evidence disappears.
An ungrounded model keeps choosing the same non-refusal answer despite evidence loss.
Research implications
Why this matters for trustworthy AI systems
MedVIGIL is not just a medical benchmark. It is a research argument: high-stakes AI systems need explicit mechanisms for evidence awareness, refusal, and uncertainty, not only better answer generation.
For medical AI, this means evaluation should test whether a model preserves the boundary between what is visually supported, what is answerable from clinical knowledge alone, and what should be deferred to a human expert.
For healthcare specifically, MedVIGIL is an evaluation suite rather than a clinical decision-support tool. Its value is in exposing silent failures before deployment, so model builders can audit whether their systems are truly grounded.
Design principles
What MedVIGIL pushes us to build
References