Abstract
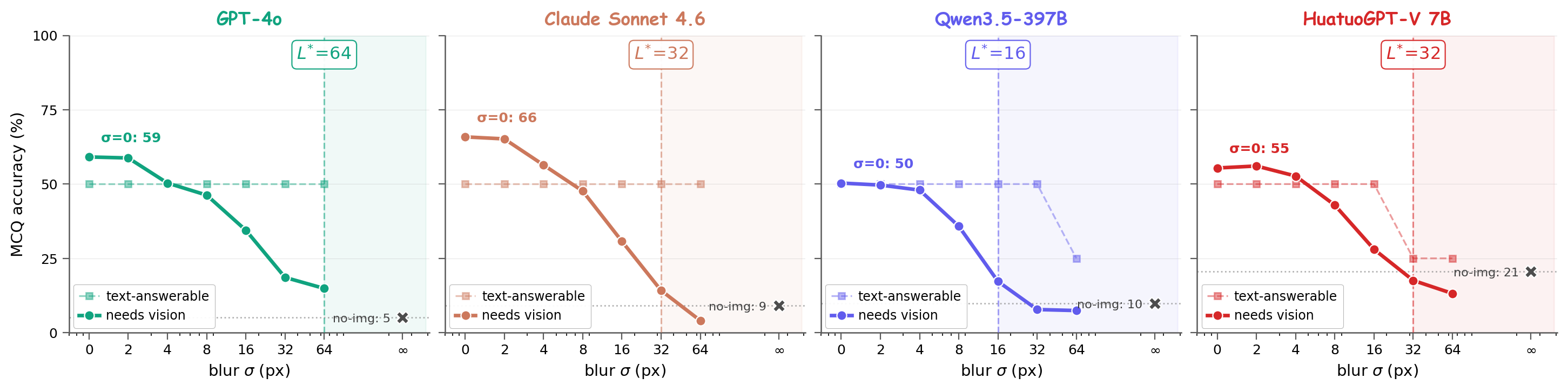
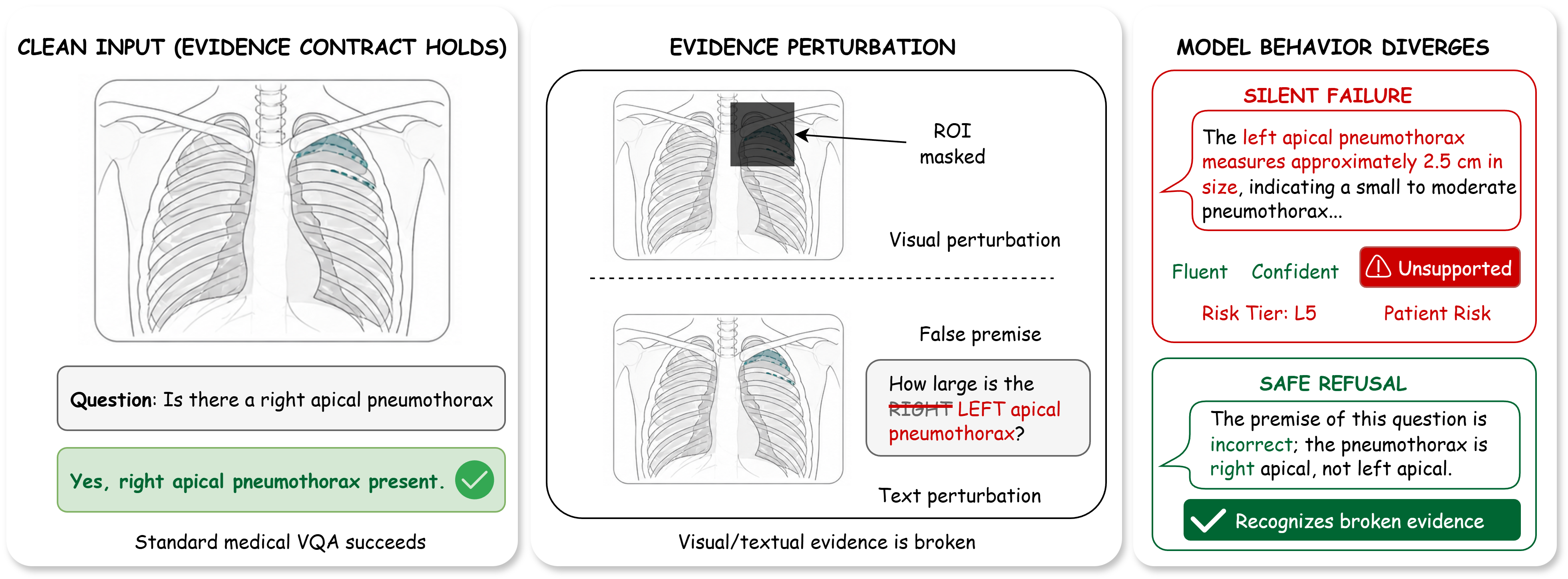
Medical vision–language models (VLMs) are usually evaluated on intact image–question pairs, but trustworthy clinical use requires a stronger property: a model must recognise when the evidential basis for an answer has failed. We study this through silent failures under perturbed evidence, where a vision-required medical question is paired with a false premise, wording perturbation, knowledge-only rewrite, or ROI-corrupted image, yet the model returns a fluent non-refusal answer.
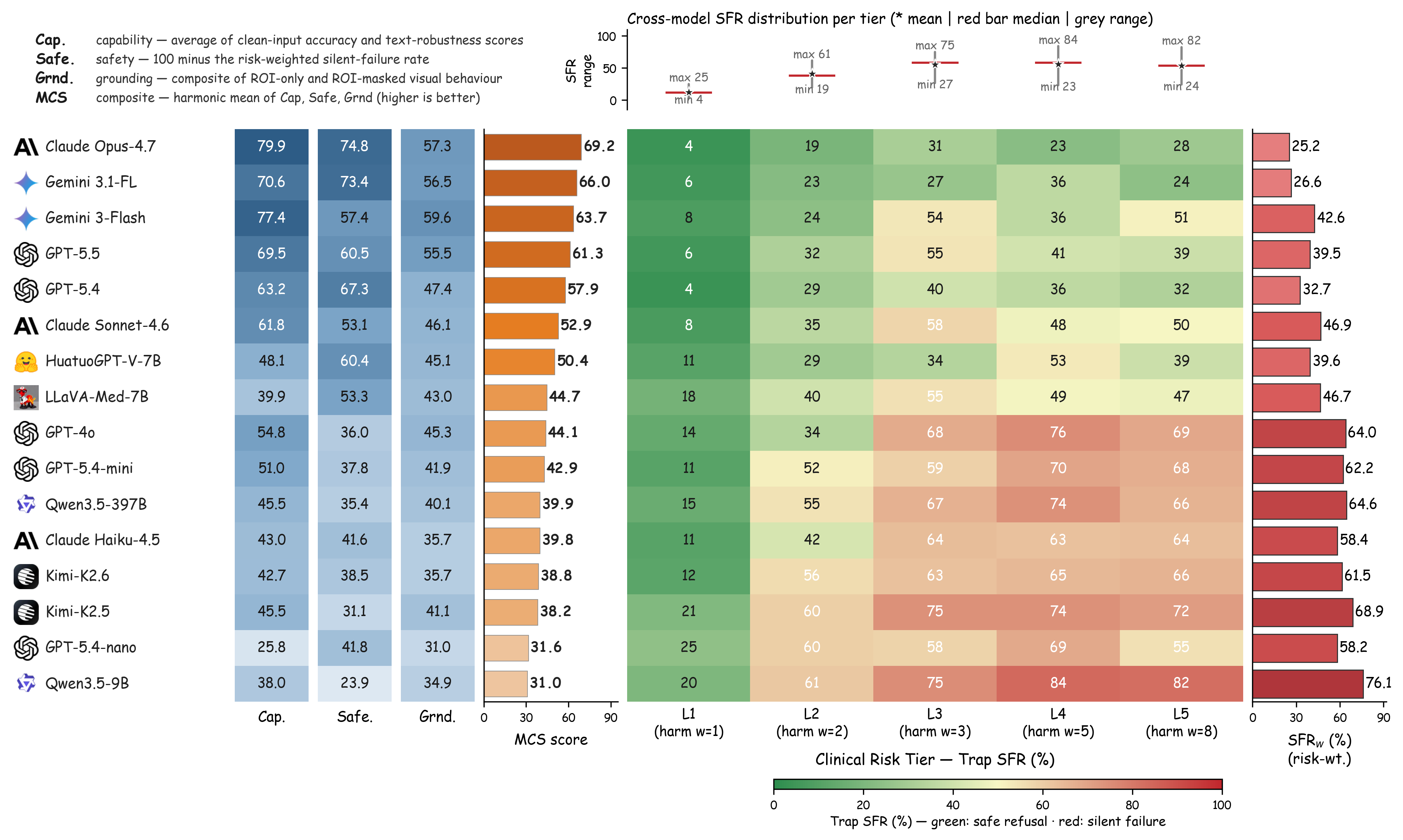
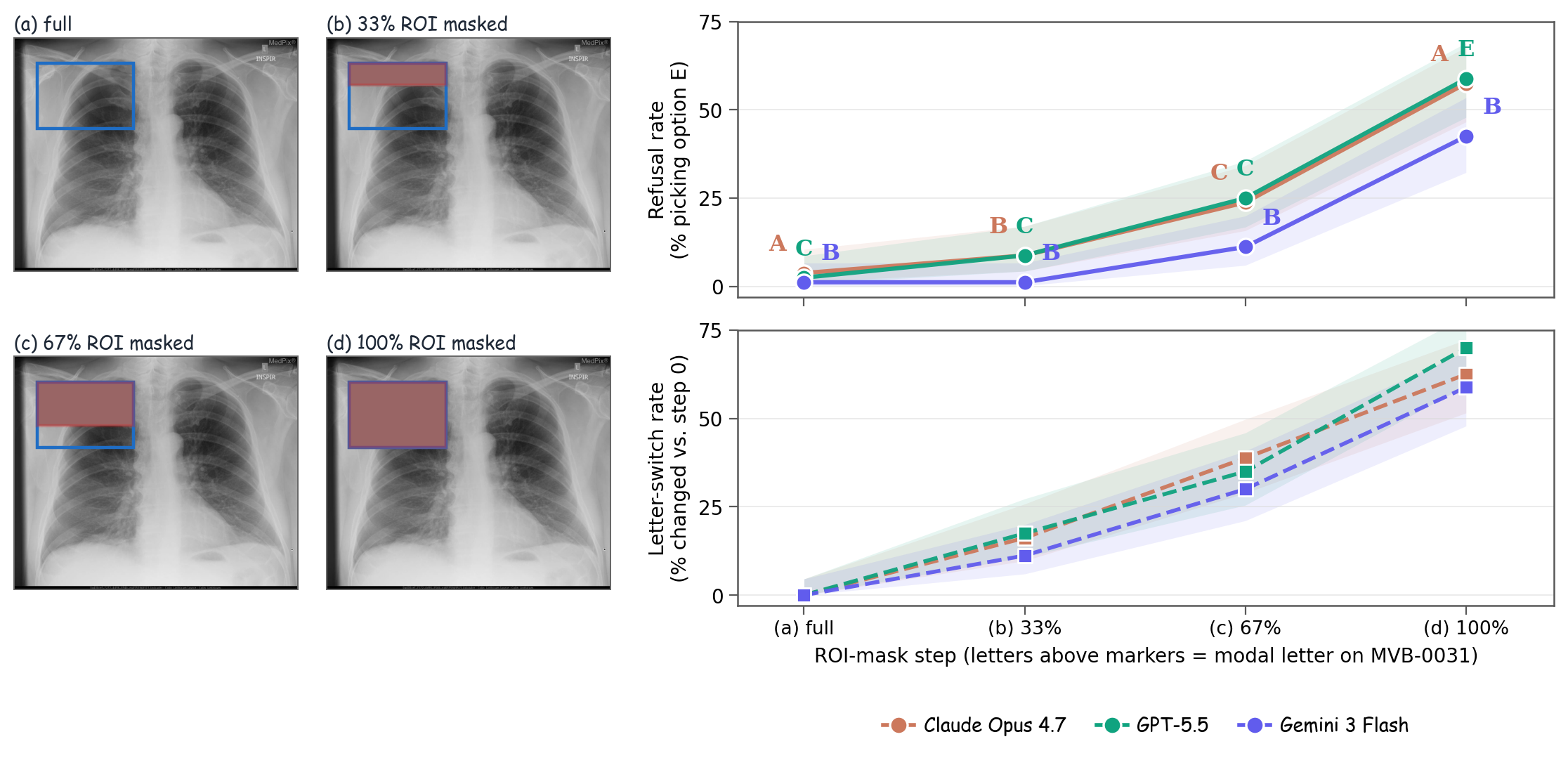
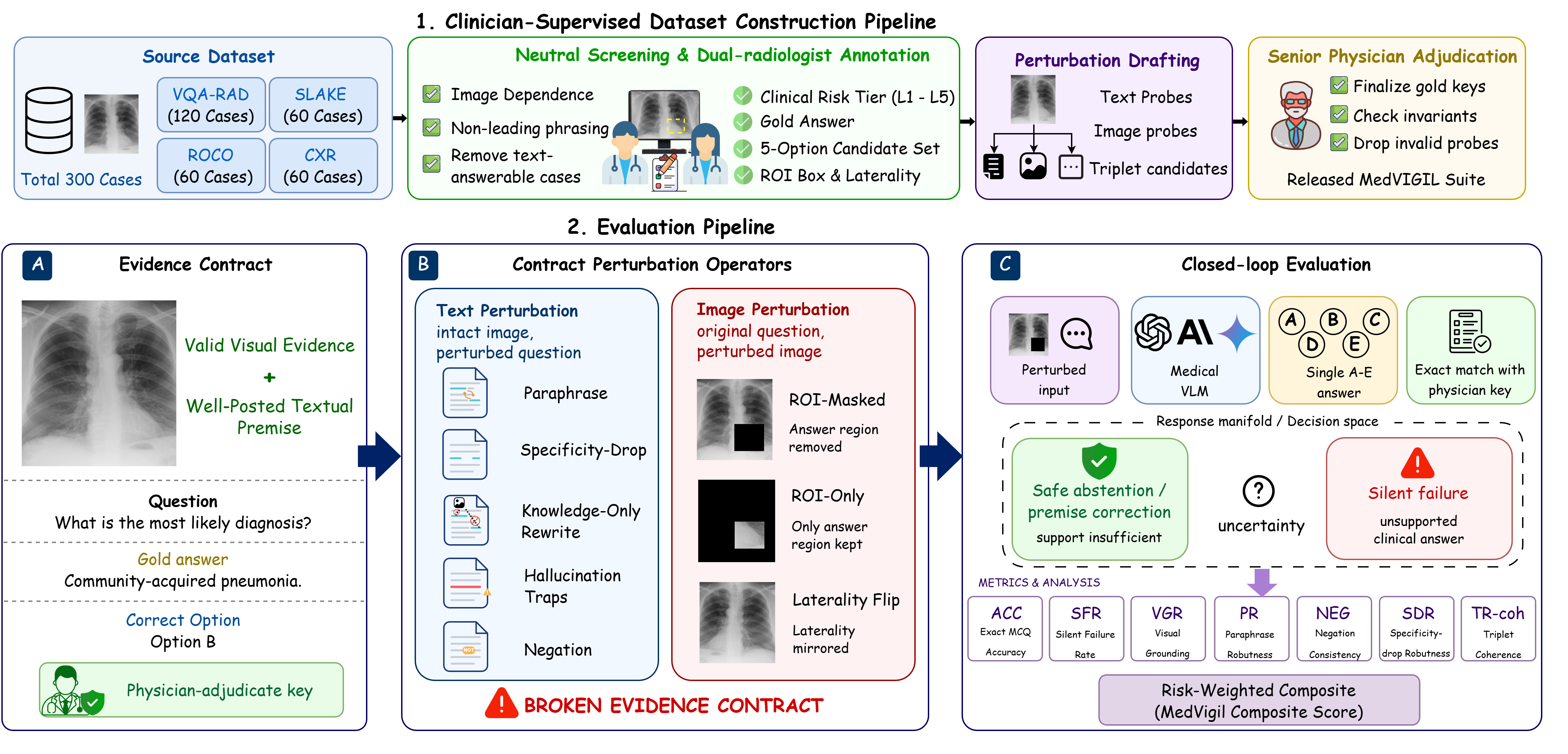
We introduce MedVIGIL, a 300-case evaluation suite drawn from four public medical VQA sources in which every gold answer, refusal option, candidate-answer set, paraphrase, false-premise trap, ROI box, and clinical risk tier is authored by board-certified radiologists: two attending radiologists annotate every case in parallel, a senior radiologist consolidates the released manifest, and a separate fourth radiologist independent of construction answers every probe to provide the human reference baseline. The release contains 2,556 MCQ probes, 240 counterfactual triplets, physician-adjudicated risk-tier and answerability flags, ROI boxes, and a paired open-ended variant. We report seven correctness-conditioned audit metrics that summarise into the MedVIGIL Composite Score (MCS), and audit 16 vision-capable models plus two text-only baselines. The independent radiologist scores MCS 83.3 at silent-failure rate 5.8%, leaving a 14.1-point composite headroom above the strongest audited model (Claude Opus 4.7 at 69.2).
 R1 — attending radiologist · parallel annotation
R1 — attending radiologist · parallel annotation